
https://www.acmicpc.net/problem/1181
1181번: 단어 정렬
첫째 줄에 단어의 개수 N이 주어진다. (1 ≤ N ≤ 20,000) 둘째 줄부터 N개의 줄에 걸쳐 알파벳 소문자로 이루어진 단어가 한 줄에 하나씩 주어진다. 주어지는 문자열의 길이는 50을 넘지 않는다.
www.acmicpc.net

1) 문제
알파벳 소문자로 이루어진 N개의 단어가 들어오면 아래와 같은 조건에 따라 정렬하는 프로그램을 작성하시오.
- 길이가 짧은 것부터
- 길이가 같으면 사전 순으로
2) 입력
첫째 줄에 단어의 개수 N이 주어진다. (1 ≤ N ≤ 20,000) 둘째 줄부터 N개의 줄에 걸쳐 알파벳 소문자로 이루어진 단어가 한 줄에 하나씩 주어진다. 주어지는 문자열의 길이는 50을 넘지 않는다.
3) 출력
조건에 따라 정렬하여 단어들을 출력한다. 단, 같은 단어가 여러 번 입력된 경우에는 한 번씩만 출력한다.
예제 입력

[접근 방법]
1. Vector STL 의 'pair' 을 이용, first에 단어, second에 단어의 길이를 저장
2. stable_sort 를 두 번 실행한다. (첫번째엔 사전순으로 정렬, 두번째엔 길이순으로 정렬)
3. 이후 중복된 단어를 제거
이 문제에서 핵심은 문제의 조건에 있다.
1. 길이가 짧으면 것부터
2. 길이가 같으면 사전순으로
3. 중복된 단어는 한 번만 출력
저번에 풀었던 10814: 나이순 정렬 https://www.acmicpc.net/problem/10814
10814번: 나이순 정렬
온라인 저지에 가입한 사람들의 나이와 이름이 가입한 순서대로 주어진다. 이때, 회원들을 나이가 증가하는 순으로, 나이가 같으면 먼저 가입한 사람이 앞에 오는 순서로 정렬하는 프로그램을
www.acmicpc.net
위 문제와 비슷하지만 조건이 조금 다르다.
[코드 설명]
우선 compare 함수를 2개 만들어 1,2 번에 조건을 만족하도록 코드를 짠다.
bool compare1(const pair<string, int>&a, const pair<string, int>&b) {
return a.first < b.first;
}
bool compare2(const pair<string, int>&a, const pair<string, int>&b) {
return a.second < b.second;
}
여기서 벡터의 first, second 인자는 각각 단어와 단어의 길이라고 정했다. 즉,
for (int i = 0; i < N; i++) {
string s;
cin >> s;
v[i].first = s;
v[i].second = s.length();
}
위처럼 vector first 에 단어값을 받으며 second 엔 단어의 길이가 바로 저장되도록 for문을 짰다.
다시 compare 함수로 넘어와서 compare1 의 경우엔 단어를 사전순으로, compare2 는 단어의 길이순으로
정렬하기 위한 함수다. 그렇다면 stable_sort 도 두번 작성해주자.
stable_sort(v.begin(), v.end(), compare1);
stable_sort(v.begin(), v.end(), compare2);
여기까지 만들고 실행해보면,

정렬은 잘 됐지만 마지막 조건인 중복 원소는 제거되지 않았다.
벡터에서 중복된 원소를 제거하는 방법은 'unique' 를 쓰는 것이다.
'unique' 는 'algorithm' 헤더 내에 존재하며, vector 배열에서 중복되지 않는 원소들을 앞에서부터 채워나가는 함수이다.
또한 중복되지 않은 원소들 뒤에 중복된 원소의 남은 부분이 존재한다.
예를 들어 v={1,2,2,3,4,4,4,5} 였다면 unique를 사용했을 때 {1,2,3,4,5,2,4,4} 로 변한다는 말이다.
사용법은 unique(v.begin(),v.end()) 이다.
이제 중복 원소를 제거하는 코드를 작성해야 한다. 이는 'erase' 를 이용하면 된다.
'erase' 역시 v.begin() 부터 v.end() 까지 제거하는 함수이기에
v.erase(unique(v.begin(),v.end()),v.end())
위처럼 작성해주면 벡터 v의 중복된 원소들은 모두 날아간다.
이 코드를 넣고 다시 프로그램을 실행해보면
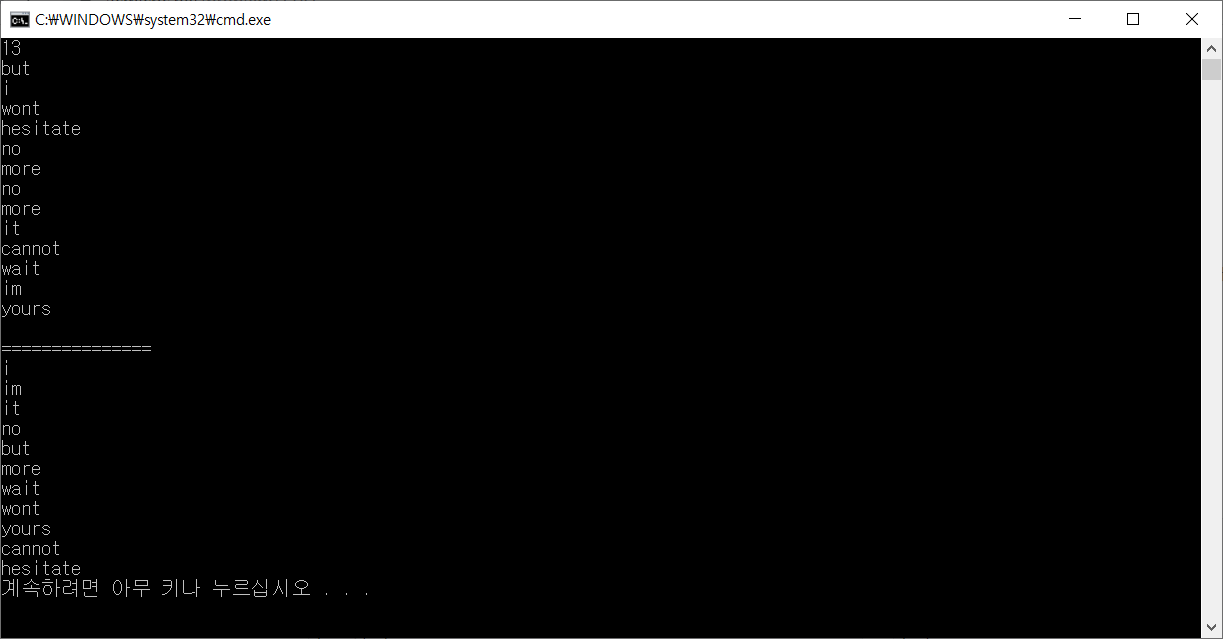
우리가 원하는 답을 도출해낼 수 있다.
[ 최종 코드 ]
#include <iostream>
#include <string>
#include <algorithm>
#include <vector>
using namespace std;
bool compare1(const pair<string, int>&a, const pair<string, int>&b) {
return a.first < b.first;
}
bool compare2(const pair<string, int>&a, const pair<string, int>&b) {
return a.second < b.second;
}
int main(void) {
int N;
cin >> N;
vector <pair<string, int>> v(N);
for (int i = 0; i < N; i++) {
string s;
cin >> s;
v[i].first = s;
v[i].second = s.length();
}
stable_sort(v.begin(), v.end(), compare1);
stable_sort(v.begin(), v.end(), compare2);
v.erase(unique(v.begin(), v.end()), v.end());
for (int i = 0; i < v.size(); i++)
cout << v[i].first << "\n";
}
최대한 짧고 간결하게 작성하고 싶었지만 아직은 이게 최선이다.
[느낀점]
중복된 단어를 도출할 수 있는 'unique' 함수에 대해 알 수 있었다.
처음에 'erase' 를 통해 지운다는 것은 상상도 못하다가 구글링을 통해 알게 되었다.
사실 'unique' 함수는 이외에도 많이 활용할 수 있다. 그런 문제들도 차차 풀어볼 것이다.

